环境
本文所有操作都在Ubuntu 14.04 Trusty环境下执行,使用Cloudera CDH5.7.1版本作为Hadoop集群版本。
Hadoop 2.6.0-cdh5.7.1
Spark 1.6.0
前言
Cloudera官方申明表示CDH5.7.1版本依旧不支持Spark的部分组件,如SparkR,并且官方论坛的讨论帖中也没有给出具体的解决时间。
本文基于这篇博文,实验了在CDH集群中部署R环境和sparkR的可能性。
安装R语言环境
请确保以下操作在集群中每个节点都执行
本段依据这篇博文进行,但是根据过程稍有不同。
首先在这里https://cran.r-project.org/mirrors.html根据位置选择一个合适的CRAN镜像,我选择了清华大学的https://mirrors.tuna.tsinghua.edu.cn/CRAN/bin/linux/ubuntu
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys E084DAB9
gpg -a --export E084DAB9 | sudo apt-key add -
LVERSION=`lsb_release -c | cut -c 11-` #trusty
echo deb https://mirrors.tuna.tsinghua.edu.cn/CRAN/bin/linux/ubuntu $LVERSION/ | sudo tee -a /etc/apt/sources.list #deb https://mirrors.tuna.tsinghua.edu.cn/CRAN/bin/linux/ubuntu trusty/
sudo apt-get update
sudo apt-get install r-base -y #r-base package
sudo apt-get install r-base-dev -y #r-base-dev package
安装完毕以后,就可以测试以下R是否正常使用了。
$ R
R version 3.3.1 (2016-06-21) -- "Bug in Your Hair"
Copyright (C) 2016 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
Natural language support but running in an English locale
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
> q()
配置rJava
$ su # 使用root用户(我的环境下sudo R CMD javareconf -e无法正常使用)
$ R CMD javareconf -e
Java interpreter : /usr/java/jdk1.8.0_77/jre/bin/java
Java version : 1.8.0_77
Java home path : /usr/java/jdk1.8.0_77
Java compiler : /usr/java/jdk1.8.0_77/bin/javac
Java headers gen.: /usr/java/jdk1.8.0_77/bin/javah
Java archive tool: /usr/java/jdk1.8.0_77/bin/jar
trying to compile and link a JNI program
detected JNI cpp flags : -I$(JAVA_HOME)/include -I$(JAVA_HOME)/include/linux
detected JNI linker flags : -L$(JAVA_HOME)/jre/lib/amd64/server -ljvm
gcc -std=gnu99 -I/usr/share/R/include -DNDEBUG -I/usr/java/jdk1.8.0_77/include -I/usr/java/jdk1.8.0_77/include/linux -fpic -g -O2 -fstack-protector --param=ssp-buffer-size=4 -Wformat -Werror=format-security -D_FORTIFY_SOURCE=2 -g -c conftest.c -o conftest.o
gcc -std=gnu99 -shared -L/usr/lib/R/lib -Wl,-Bsymbolic-functions -Wl,-z,relro -o conftest.so conftest.o -L/usr/java/jdk1.8.0_77/jre/lib/amd64/server -ljvm -L/usr/lib/R/lib -lR
The following Java variables have been exported:
JAVA_HOME JAVA JAVAC JAVAH JAR JAVA_LIBS JAVA_CPPFLAGS JAVA_LD_LIBRARY_PATH
Running: /bin/bash
$ export LD_LIBRARY_PATH=$JAVA_LD_LIBRARY_PATH
$ R
install.packages("rJava")
下载Spark1.6.0原版
请确保以下操作在集群中每个节点都执行
从Spark官网的下载地址下载和CDH搭配的Spark版本相同的版本,这里我下载了spark-1.6.0-bin-hadoop2.6

解压缩
tar zxvf spark-1.6.0-bin-hadoop2.6.tgz
cd spark-1.6.0-bin-hadoop2.6
确定下CDH中的文件权限
$ ll /opt/cloudera/parcels/CDH/lib/spark/
total 80
drwxr-xr-x 9 root root 4096 6月 2 08:20 ./
drwxr-xr-x 37 root root 4096 6月 2 08:23 ../
drwxr-xr-x 3 root root 4096 6月 2 07:48 assembly/
drwxr-xr-x 2 root root 4096 6月 2 07:48 bin/
drwxr-xr-x 2 root root 4096 6月 2 07:48 cloudera/
lrwxrwxrwx 1 root root 15 6月 2 07:48 conf -> /etc/spark/conf/
drwxr-xr-x 3 root root 4096 6月 2 07:48 examples/
drwxr-xr-x 2 root root 4096 6月 2 08:24 lib/
-rw-r--r-- 1 root root 17352 6月 2 07:48 LICENSE
-rw-r--r-- 1 root root 23529 6月 2 07:48 NOTICE
drwxr-xr-x 6 root root 4096 6月 2 07:48 python/
-rw-r--r-- 1 root root 0 6月 2 07:48 RELEASE
drwxr-xr-x 2 root root 4096 6月 2 07:48 sbin/
lrwxrwxrwx 1 root root 19 6月 2 07:48 work -> /var/run/spark/work
复制R文件夹到/opt/cloudera/parcels/CDH/lib/spark/中
sudo cp -R R /opt/cloudera/parcels/CDH/lib/spark/R
再确定下权限是否正确
ll /opt/cloudera/parcels/CDH/lib/spark/
total 84
drwxr-xr-x 10 root root 4096 7月 13 14:52 ./
drwxr-xr-x 37 root root 4096 6月 2 08:23 ../
drwxr-xr-x 3 root root 4096 6月 2 07:48 assembly/
drwxr-xr-x 2 root root 4096 6月 2 07:48 bin/
drwxr-xr-x 2 root root 4096 6月 2 07:48 cloudera/
lrwxrwxrwx 1 root root 15 6月 2 07:48 conf -> /etc/spark/conf/
drwxr-xr-x 3 root root 4096 6月 2 07:48 examples/
drwxr-xr-x 2 root root 4096 6月 2 08:24 lib/
-rw-r--r-- 1 root root 17352 6月 2 07:48 LICENSE
-rw-r--r-- 1 root root 23529 6月 2 07:48 NOTICE
drwxr-xr-x 6 root root 4096 6月 2 07:48 python/
drwxr-xr-x 3 root root 4096 7月 13 14:52 R/
-rw-r--r-- 1 root root 0 6月 2 07:48 RELEASE
drwxr-xr-x 2 root root 4096 6月 2 07:48 sbin/
lrwxrwxrwx 1 root root 19 6月 2 07:48 work -> /var/run/spark/work
备份CDH中Spark的bin目录和sbin目录
sudo cp -R /opt/cloudera/parcels/CDH/lib/spark/bin /opt/cloudera/parcels/CDH/lib/spark/bin.bak
sudo cp -R /opt/cloudera/parcels/CDH/lib/spark/sbin /opt/cloudera/parcels/CDH/lib/spark/sbin.bak
使用下载的Spark中的bin和sbin覆盖
sudo cp bin/* /opt/cloudera/parcels/CDH/lib/spark/bin/
sudo cp sbin/* /opt/cloudera/parcels/CDH/lib/spark/sbin/
配置本地的环境变量
source /etc/spark/conf/spark-env.sh
切换到正确的用户,就可以启动sparkR了
$ su hdfs
$ sparkR
.............................
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.6.0
/_/
Spark context is available as sc, SQL context is available as sqlContext
> x <- 0
> x
[1] 0
我们可以测试以下spark源码中自带的example来看看效果
ml.r
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# To run this example use
# ./bin/sparkR examples/src/main/r/ml.R
# Load SparkR library into your R session
library(SparkR)
# Initialize SparkContext and SQLContext
sc <- sparkR.init(appName="SparkR-ML-example")
sqlContext <- sparkRSQL.init(sc)
# Train GLM of family 'gaussian'
training1 <- suppressWarnings(createDataFrame(sqlContext, iris))
test1 <- training1
model1 <- glm(Sepal_Length ~ Sepal_Width + Species, training1, family = "gaussian")
# Model summary
summary(model1)
# Prediction
predictions1 <- predict(model1, test1)
head(select(predictions1, "Sepal_Length", "prediction"))
# Train GLM of family 'binomial'
training2 <- filter(training1, training1$Species != "setosa")
test2 <- training2
model2 <- glm(Species ~ Sepal_Length + Sepal_Width, data = training2, family = "binomial")
# Model summary
summary(model2)
# Prediction (Currently the output of prediction for binomial GLM is the indexed label,
# we need to transform back to the original string label later)
predictions2 <- predict(model2, test2)
head(select(predictions2, "Species", "prediction"))
# Stop the SparkContext now
sparkR.stop()
使用spark-submit提交到YARN中
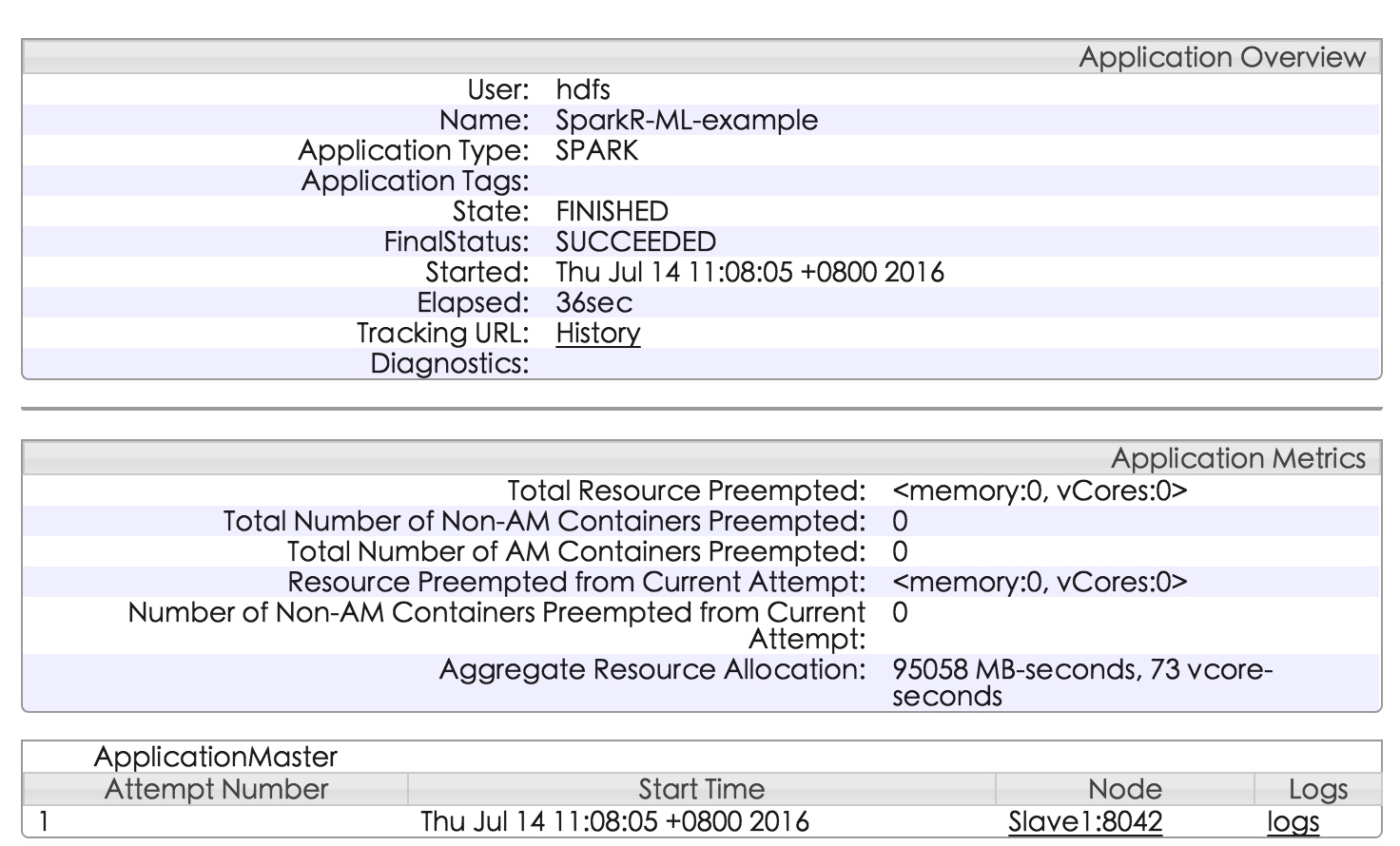
$ spark-submit --master=yarn --num-executors 4 ml.R
没有错误执行完就可以看到结果了,并且可以在YARN的管理界面看到
附录 批量执行代码
nodes="`cat /etc/hosts | grep -i node | awk '{print $2}'`"
for target in $nodes; do
echo $target "=================="
scp -r /home/free/spark-1.6.0-bin-hadoop2.6/R root@$target:/opt/cloudera/parcels/CDH/lib/spark/R
done
for target in $nodes; do
echo $target "=================="
ssh -o StrictHostKeyChecking=no root@$target "cp -R /opt/cloudera/parcels/CDH/lib/spark/bin /opt/cloudera/parcels/CDH/lib/spark/bin.bak"
done
for target in $nodes; do
echo $target "=================="
ssh -o StrictHostKeyChecking=no root@$target "cp -R /opt/cloudera/parcels/CDH/lib/spark/sbin /opt/cloudera/parcels/CDH/lib/spark/sbin.bak"
done
for target in $nodes; do
echo $target "=================="
scp -r /home/free/spark-1.6.0-bin-hadoop2.6/bin/* root@$target:/bin/
done
for target in $nodes; do
echo $target "=================="
scp -r /home/free/spark-1.6.0-bin-hadoop2.6/sbin root@$target:/opt/cloudera/parcels/CDH/lib/spark/sbin
done
for target in $nodes; do
echo $target "=================="
ssh -o StrictHostKeyChecking=no root@$target "mv /opt/cloudera/parcels/CDH/lib/spark/bin/bin/* /opt/cloudera/parcels/CDH/lib/spark/bin/"
done
for target in $nodes; do
echo $target "=================="
ssh -o StrictHostKeyChecking=no root@$target "mv /opt/cloudera/parcels/CDH/lib/spark/sbin/sbin/* /opt/cloudera/parcels/CDH/lib/spark/sbin/"
done
for target in $nodes; do
echo $target "=================="
ssh -o StrictHostKeyChecking=no root@$target "rm -r /opt/cloudera/parcels/CDH/lib/spark/bin/bin/"
done
for target in $nodes; do
echo $target "=================="
ssh -o StrictHostKeyChecking=no root@$target "rm -r /opt/cloudera/parcels/CDH/lib/spark/sbin/sbin/"
done
后续
为了防止官网下载的版本和Cloudera CDH兼容性存在问题,我重新使用Cloudera Spark的源码编译了一份对应版本的Spark,详细的过程请参考这篇文章。